Lab 4: Added Variable Plots and Bootstrapping
PSYC 7804 - Regression with Lab
Added variable plots
Then, added variables plots are simply plots between the residuals of one the predictors and \(Y\) that result by removing the variance explained by all the other variables.
ggplot() +
geom_point(aes(y = resid_happy_Free,
x = resid_corr))
ggplot() +
geom_point(aes(y = resid_happy_corr,
x = resid_Free))
The slopes that you get when you include both predictors are the slopes for the lines of best fit these 2 plots.
The Quick way: car::avPlots()
car::avPlots(reg_full)
To get added variable plots in practice you would use the avPlot() function.
When you have more than 2 predictors, it is not possible to build a visualization of all variables at once like a 3D plot. Added variable plots can help you visualize regression results no matter the number of predictors!
Bootstrapping
Bootstrapping (Efron, 1992) is a really smart idea to calculate confidence intervals while avoid doing math! You probably have seen some complicated equations that need to be derived to calculate confidence intervals for statistics (e.g., see here for the 95% CI of \(R^2\)).
Turns out that even more complex math goes behind deriving the complicated equations 😱 Usually, that involves figuring out what is the theoretical sampling distribution of a certain statistic for an infinite number of experiments.
Instead bootstrapping says:
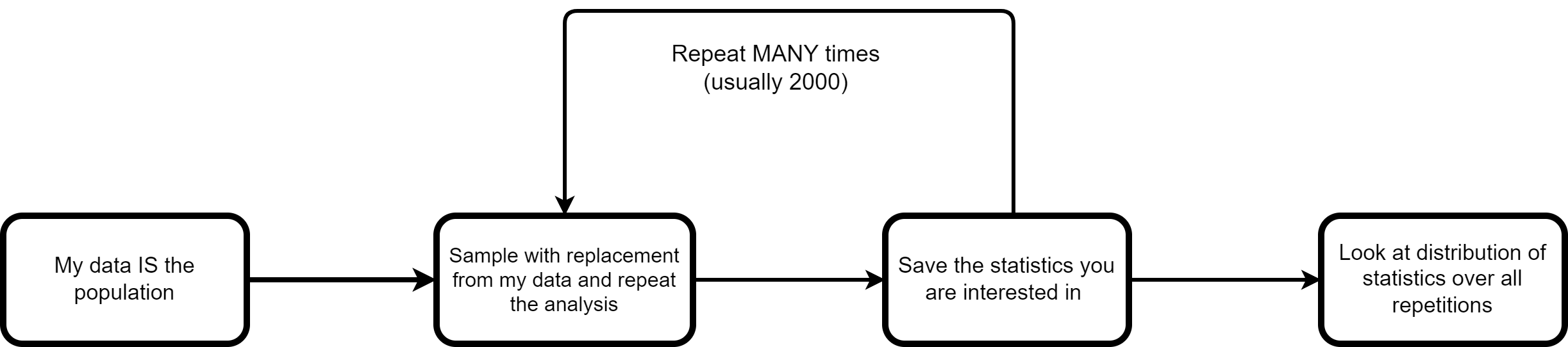
“By Hand” Example of Bootstrapping
As always, we can do things ourselves to get a better understanding of the process.
Bootstrap \(R^2\) code
# empty element to save R^2 to
r_squared <- c()
reg_vars <- dat[, c("Happiness_score",
"Corruption",
"Freedom")]
set.seed(34677)
for(i in 1:2000){
# sample from data
sample <- sample(1:nrow(reg_vars),
replace = TRUE)
dat_boot <- reg_vars[sample,]
# Run regression
reg_boot <- lm(Happiness_score ~ Corruption + Freedom,
dat_boot)
# Save R^2
r_squared[i] <- summary(reg_boot)$r.squared
}There is a lot of value in understanding how the code above works, but the main point is that we are running the same regression 2000 times with a different sample from our data, and then saving the \(R^2\) that we get every time.
The \(R^2\) from our regression with both variables was
summary(reg_full)$r.squared[1] 0.4753323We mostly care about the 95% confidence interval.
If we look out the distribution of the all the 2000 \(R^2\) we get
hist(r_squared)
quantile(r_squared, c(.025, .5, .975)) 2.5% 50% 97.5%
0.3373832 0.4793844 0.6113752 Visualizing Bootstrap Results
You can also visualize the distribution of the bootstrapped samples for the regression slopes.
NOTE: You need to provide the names of the regression slopes as shown in the
summary() output through the parm= argument
hist(boot_model,
parm = c("Corruption",
"Freedom"))Notice that the bootstrap samples are very normally distributed. This is almost always the case for regression slopes. In contrast, statistics like \(R^2\) will not be normally distributed as we saw 2 slides ago.
